

{kind=link}
Open fashions are driving a brand new wave of on-device AI, extending innovation past the cloud to on a regular basis gadgets. As these fashions advance, their worth more and more relies on entry to native, real-time context that may flip significant insights into motion.
Designed for this shift, Google’s newest additions to the Gemma 4 household introduce a category of small, quick and omni-capable fashions constructed for environment friendly native execution throughout a variety of gadgets.
Google and NVIDIA have collaborated to optimize Gemma 4 for NVIDIA GPUs, enabling environment friendly efficiency throughout a variety of methods — from knowledge middle deployments to NVIDIA RTX-powered PCs and workstations, the NVIDIA DGX Spark private AI supercomputer and NVIDIA Jetson Orin Nano edge AI modules.
Gemma 4: Compact Fashions Optimized for NVIDIA GPUs
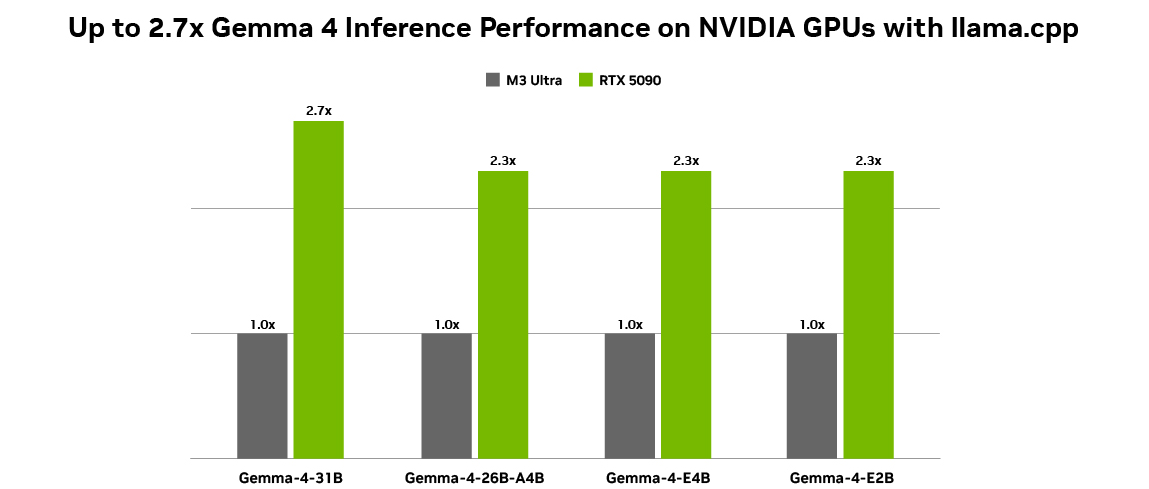
The newest additions to the Gemma 4 household of open fashions— spanning E2B, E4B, 26B and 31B variants — are designed for environment friendly deployment from edge gadgets to high-performance GPUs.
This new era of compact fashions helps a variety of duties, together with:
- Reasoning: Robust efficiency on complicated problem-solving duties.
- Coding: Code era and debugging for developer workflows.
- Brokers: Native assist for structured software use (perform calling).
- Imaginative and prescient, Video and Audio Capabilities: Enables wealthy multimodal interactions for object recognition, automated speech recognition, and doc or video intelligence.
- Interleaved Multimodal Enter: Mix textual content and pictures in any order inside a single immediate.
- Multilingual: Out-of-the-box assist for 35+ languages, pretrained on 140+ languages.
The E2B and E4B fashions are constructed for ultraefficient, low-latency inference on the edge, operating utterly offline with near-zero latency throughout many gadgets together with Jetson Nano modules.
The 26B and 31B fashionsare designed for high-performance reasoning and developer-centric workflows, making them nicely fitted to agentic AI. Optimized to ship state-of-the-art, accessible reasoning, these fashions run effectively on NVIDIA RTX GPUs and DGX Spark — powering growth environments, coding assistants and agent-driven workflows.
As native agentic AI continues to achieve momentum, functions like OpenClaw are enabling always-on AI assistants on RTX PCs, workstations and DGX Spark. The newest Gemma 4 fashions are suitable with OpenClaw, permitting customers to construct succesful native brokers that draw context from private recordsdata, functions and workflows to automate duties. Discover ways to run OpenClaw without spending a dime on RTX GPUs and DGX Spark or utilizing the DGX Spark OpenClaw playbook.
Getting Began: Gemma 4 on RTX GPUs and DGX Spark
NVIDIA has collaborated with Ollama and llama.cpp to supply the most effective native deployment expertise for every of the Gemma 4 fashions.
To use Gemma 4 regionally, customers can obtain Ollama to run Gemma 4 fashions or set up llama.cpp and pair it with the Gemma 4 GGUF Hugging Face checkpoint. Moreover, Unsloth offers day-one assist with optimized and quantized fashions for environment friendly native fine-tuning and deployment by way of Unsloth Studio. Begin operating and fine-tuning Gemma 4 in Unsloth Studio at present.
Working open fashions just like the Gemma 4 household on NVIDIA GPUs achieves optimum efficiency as a result of NVIDIA Tensor Cores speed up AI inference workloads to ship greater throughput and decrease latency for native execution. Plus, the CUDA software program stack ensures broad compatibility throughout main frameworks and instruments, enabling new fashions to run effectively from day one.
This mix permits open fashions like Gemma 4 to scale throughout a variety of methods — from Jetson Orin Nano on the edge to RTX PCs, workstations and DGX Spark — with out requiring intensive optimization.
Try the NVIDIA technical weblog for extra particulars on the way to get began with Gemma 4 on NVIDIA GPUs and be taught extra about NVIDIA’s work on open fashions.
#ICYMI: The Newest Updates for RTX AI PCs
✨ Atone for RTX AI Storage blogs for a bunch of agentic AI bulletins from NVIDIA GTC, reminiscent of new open fashions for native brokers. These fashions embody NVIDIA Nemotron 3 Nano 4B and Nemotron 3 Tremendous 120B, and optimizations for Qwen 3.5 and Mistral Small 4.
NVIDIA not too long ago launched NVIDIA NemoClaw, an open supply stack that optimizes OpenClaw experiences on NVIDIA gadgets by growing safety and supporting native fashions.
🚀 Accomplish.ai introduced Accomplish FREE, a no-cost model of its open supply desktop AI agent with built-in fashions. It harnesses NVIDIA GPUs to run open weight fashions regionally, whereas a hybrid router dynamically balances workloads between native RTX {hardware} and the cloud — enabling quick, non-public, zero-configuration execution with out requiring an software programming interface key.
Plug in to NVIDIA AI PC on Fb, Instagram, TikTok and X — and keep knowledgeable by subscribing to the RTX AI PC e-newsletter.